mysql
SQL基础:
联表查询:
用join比where效率高
group by:
通常和聚合函数一起使用
in和exact:
in:左边的表达式在右边的列表中就返回true
exact:子查询语句能查到数据就返回true
varchar和char:
char是定长的,效率高
varchar是变长的,节省空间
int(1)和int(10)有什么不同:
只是会在小于位数的时候有补零显示
索引:
索引是为了提高搜索的效率,通过普通索引搜索会进行回表(这是最优的查询方式)。
要想提高效率只能提高回表效率,提高回表效率的方式有索引覆盖和索引下推。
索引覆盖:普通索引的B+树中信息涵盖了要查询的信息,直接不用回表了
索引下推:把 WHERE 里没用到索引的条件推到引擎层提前过滤,减少回表,变快。(没有索引下推的时候一般只会在引擎层查询一个字段)
什么时候索引会失效(因为写的条件使用索引的效率不高,优化器自动跳过索引进行全表扫描):
违反最左匹配原则:没有按照联合索引的顺序搜索
反向匹配:用!=
对索引列进行操作:函数操作,数值计算,类型转换
or查询:如果有列不在索引中
创建索引的原则:
发挥索引覆盖和索引下推的优势
不为离散度低的列创建索引
只为进行搜索,排序,分组的列创建索引
用好联合索引(1:不要为联合索引的第一个索引列单独创建索引(浪费空间,并且还浪费时间去维护),2:建立联合索引的时候,一定要把最常用的列放在最左边)
对长字段创建前缀索引
频繁更新的列不要作为主键或者索引
是什么:
类似目录结构,提高搜索效率的。
怎么实现的:
以页为单位进行数据交换
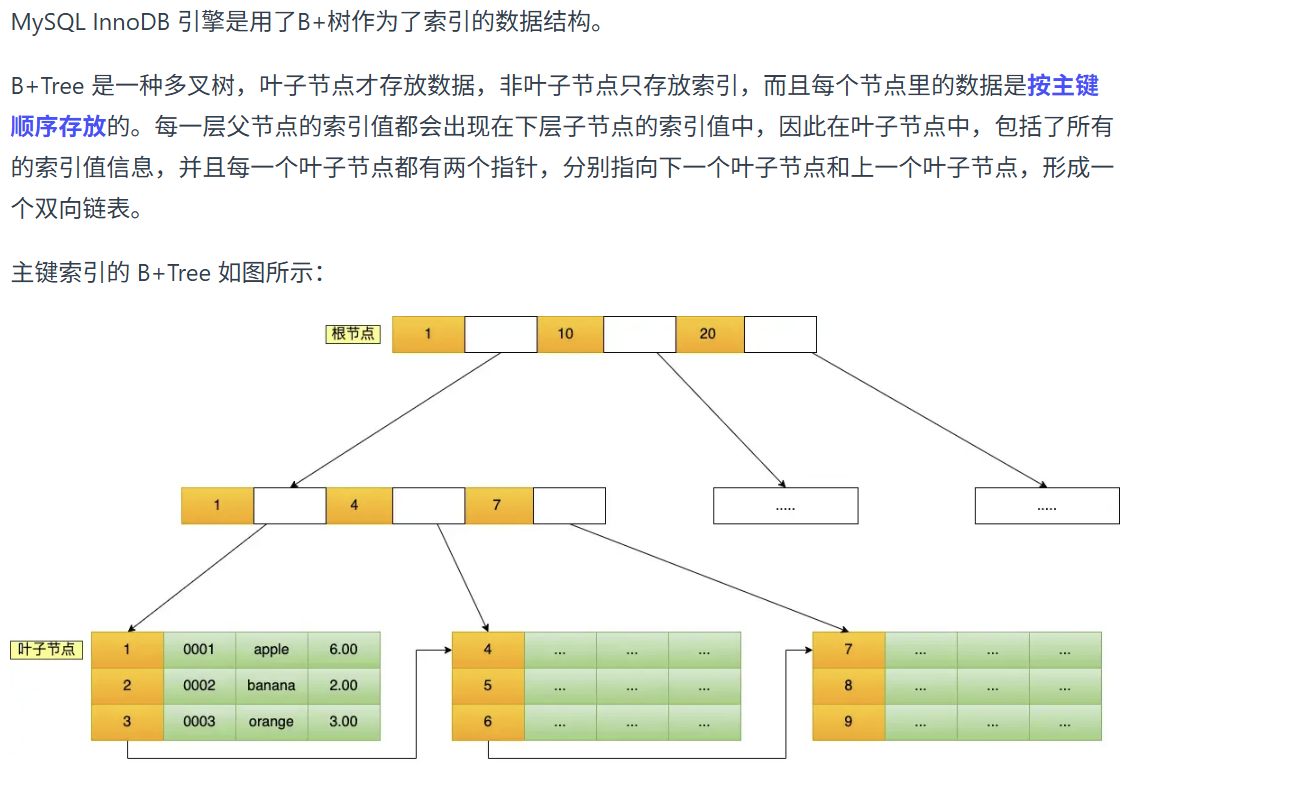
到叶子节点怎么查询:
数据也按照主键顺序组成单项链表,通过遍历可以找到节点,并且数据页中还有页目录来提高查找效率
聚族索引和非聚族索引的区别:
聚族索引通常由主键构造的,只有聚族索引的叶子节点包含完整信息,通过非聚族索引查找信息需要进行“回表”
锁:
有哪些行级锁:
• 记录锁(record lock)——锁具体一行
• 间隙锁(gap lock)——锁两个索引键之间的“空隙”
• Next-key lock——上面两者合体(左闭右开区间)
插入意向锁:如果没有插入意向锁,插入请求在往间隙中插入信息的操作就变成了串行
事务:
事务的特性和实现:
特性:
原子性,持久性,隔离性,一致性
实现:
持久性通过redolog来实现
原子性通过undolog来实现
隔离性通过MVCC或锁机制来实现
一致性是通过持久性,原子性,隔离性来实现
mysql可能出现什么并发问题:
脏读:
读到了未提交事务修改的数据
不可重复度:
在事务期间有其他事务提交读到了其修改的数据
幻读:
在事务期间查询符合某个条件的数据数量不同
mysql如何解决并发问题的:
锁机制和事务隔离级别
事务的隔离级别有哪些:

可重复读隔离级别:
如何实现的:
在执行第一个查询语句时候创建Readview
如何在可重复读隔离级别下避免幻读问题:
通过当前读语句SELECT … FOR UPDATE给数据加上next-key lock
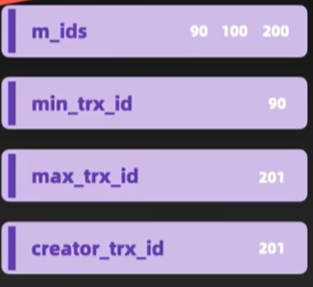
介绍MVCC实现原理:
每个事务都有一个ReadView,根据这个ReadView去找对应数据的undolog版本链符合的信息.
undolog链:
第一条在数据页中,下面的在undolog日志中

Readview快照:
日志:
日志分成哪几类:
undolog:回滚日志,实现了事务的原子性,用于MVCC和事务回滚
redolog:重做日志,实现了事务的持久性,用于掉电等故障的恢复
binlog:二进制日志,是Server层生成的日志,用于数据备份和主从复制
undolog:
讲一下undolog:
事务未提交时,将更新前的数据存到undolog日志文件中。
binlog:
讲一下binlog:
完成一个修改数据的操作,Server会生成一条binlog,事务提交的时候就会写入binlog文件。
能不能只用binlog不用redolog:
binlog是server层日志,没办法记录哪些脏页还没有刷盘
redolog(redolog刷盘成功标志事务提交成功):
1:为什么要有redolog
实现事务的持久性,保证数据库在任何时刻发生崩溃,重启之后已经提交的记录不会消失
将写操作从随机写变成了顺序写(数据不先写回磁盘,后台定期将脏页刷回磁盘)
2:redolog是存在内存中吗
在事务执行过程中会在内存中,事务提交之后就会写到磁盘中
3:怎么保持持久性
数据写入磁盘之前发生宕机,系统可通过redolog来恢复数据
两段提交:
prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
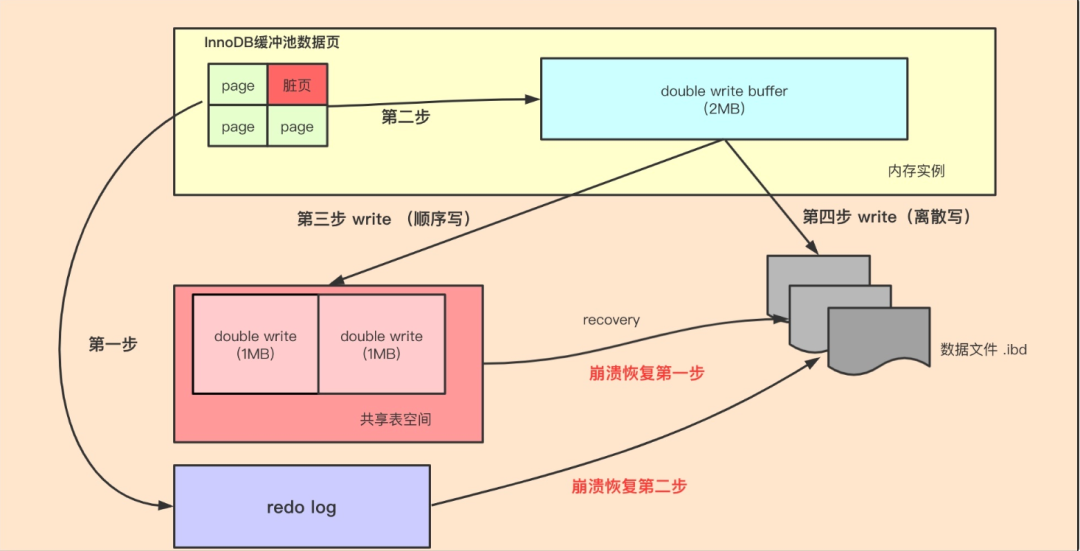
谈谈mysql的双写:
解决了什么问题:
• 如果刷脏过程中机器掉电,就可能出现页写了一部分(partial write):页头、校验和、数据内容不一致。
• 仅靠 redo log 无法修复这种物理损坏(redo 只能重做逻辑操作,不能重建半个坏页)。
触发时机:
只在“刷脏”时用到
怎么实现的: